put 'student','1','info:name','Xueqian' put 'student','1','info:gender','F' put 'student','1','info:age','23' put 'student','2','info:name','Weiliang' put 'student','2','info:gender','M' put 'student','2','info:age','24'
查看录入的数据
1 2 3 4
//如果每次只查看一行,就用下面命令 hbase> get 'student','1' //如果每次查看全部数据,就用下面命令 hbase> scan 'student'
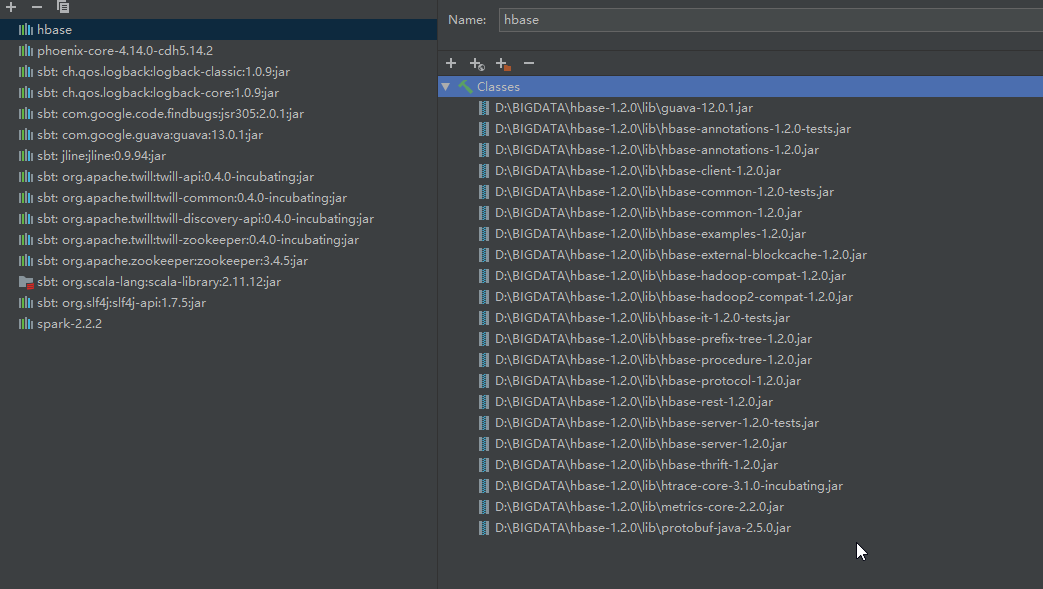
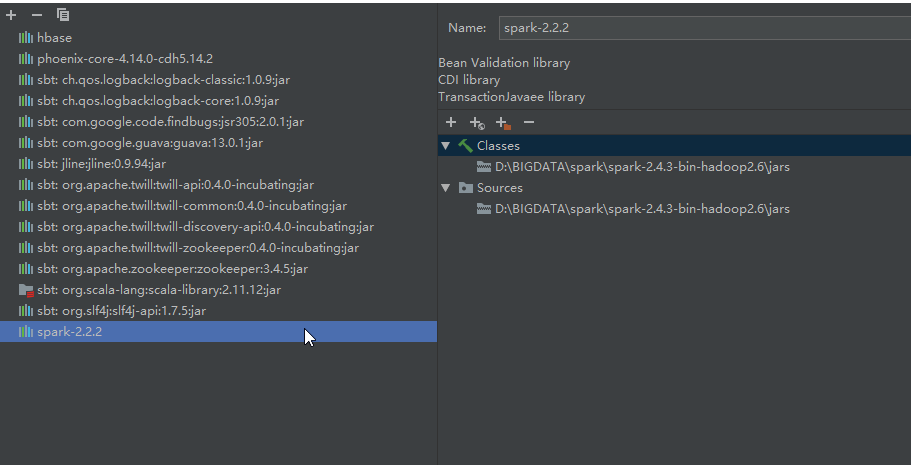
配置Spark
拷贝 hbase 的 jar 包到 D:\BIGDATA\spark\spark-1.6.2-bin-hadoop2.6\lib\下
defmain(args: Array[String]): Unit = { val sparkConf = newSparkConf().setAppName("SparkWriteHBase").setMaster("local") val sc = newSparkContext(sparkConf) val tablename = "student" sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE, tablename)
val job = newJob(sc.hadoopConfiguration) job.setOutputKeyClass(classOf[ImmutableBytesWritable]) job.setOutputValueClass(classOf[Result]) job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])
val indataRDD = sc.makeRDD(Array("3,Rongcheng,M,26", "4,Guanhua,M,27")) //构建两行记录 val rdd = indataRDD.map(_.split(',')).map { arr => { val put = newPut(Bytes.toBytes(arr(0))) //行健的值 put.add(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(arr(1))) //info:name列的值 put.add(Bytes.toBytes("info"), Bytes.toBytes("gender"), Bytes.toBytes(arr(2))) //info:gender列的值 put.add(Bytes.toBytes("info"), Bytes.toBytes("age"), Bytes.toBytes(arr(3).toInt)) //info:age列的值 (newImmutableBytesWritable, put) } } rdd.saveAsNewAPIHadoopDataset(job.getConfiguration()) } }